
On this page I will incrementally collect all the information what I currently (2023-03-12) found out looking in Dragon Quest IV Playstation 1 Remake (ドラゴンクエストIV 導かれし者たち) data. If I cannot continue this project, it may help others to get into it. You can contact me for questions, collaborations or hints.
Related source code is on GitHub. A collaborator in 2022, Mandy, has also source code on GitHub. There is also a related romhacking.net forum post and a Slime Time Dragon Quest Podcast about this topic. There is also an update in the Dragon’s Den Forum.
- Getting the data
- Other attempts in the past
- Understanding HBD1PS1D file
- Where does the dialog pointers come from? Finally, the cut scene script!
- Translation Embedding (Second Attempt)
- Understanding the cut scene script
- CD-ROM Pointers
- New Codebase
- Translation Embedding (First Proof of Concept, since 2021-12-19 deprecated)
Getting the data
I took the japanese game from coolrom. Using cebix’s psximager, the *.bin file can be extracted. You will find three files on the disk:
SYSTEM.CNF(68 Bytes) – just a small config what executable will be startedSLPM_869.16(692.2 KB) – the PS-X EXE executableHBD1PS1D.Q41(319.4 MB) – the game’s resources
The company Heart Beat Inc. both implemented Dragon Quest IV (DQ4) and Dragon Quest VII (DQ7) for the PlayStation. This is why HBD1PS1D.Q41 could mean Heart Beat Disc/Data 1 for PlayStation 1 Dragon Quest 4. Understanding this archive would allow to extract resources and also could help to translate it from japanese to english. Similarly, DQ7 has the file HBD1PS1D.Q71.
Other attempts in the past
In 2008 the user Kojiro started an initiative to translate Dragon Quest IV. However, the site is down and it seems that there was no progress. Using the Wayback Machine it is maybe helpful to look into their forum.
In 2010 the question of a translation was stated in the Dragon Den’s Forum, but without any results.
2012 a user named rveach got very far with Dragon Quest VII for a French community.
The user loveemu extracted in 2014 from the HBD1PS1D.Q41 file the music. See also the user’s Dragon Quest VII: Sound Engine Analysis. The tool psdq7rip that extracts the sound files from HBD1PS1D file just scans for sound data and does not extract the archive completely.
In 2000, Tonura mentions that in the DQ7 file there are monster images at a certain position but compressed with LZ algorithm. The Game Lab magazin (ゲームラボの記事) is mentioned here. Seems to be that the October 2000 volume is the right one.
Understanding HBD1PS1D file
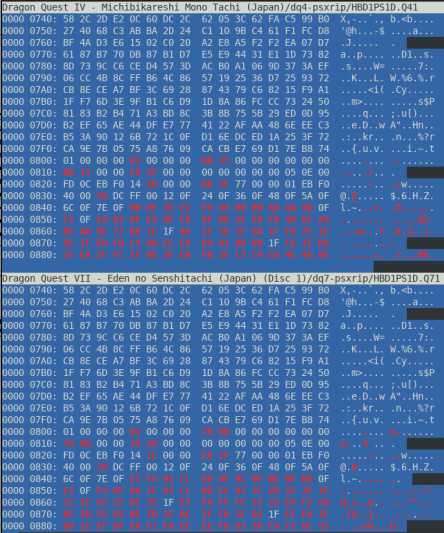
HBD1PS1D.Q41 has a size of 319436800 bytes. It perfectly divides by 2048 byte blocks: 319436800 bytes file size / 2048 bytes = 155975 blocks. In fact, when we visualize each byte of the file as a gray pixel on a 2048 x 155975 bitmap, we see certain patterns:


The pattern shows that some resources consist of more than one 2048 bytes block. We call them * 00 00 00 blocks, since they always start with this pattern. In the middle of the file are white spots: these resources have another header than the other resources. We call them 0x60010108 blocks, since they always start with this pattern.
The first 2048 bytes

The very first 2048 bytes of the HBD1PS1D (the first block) is different to the following blocks. It is noticeable that the ASCII string „hdb1ps1d.q41“ is exactly at position 0x400 (1024). Maybe we see here two 1024 byte blocks. There are rarely 0x00 bytes which is why I guess that we do not see short or int numbers here. Decompressing does not show any good data and a check with several japanese text encodings does also not show text.
When we compare DQ4 and DQ7, we see that the first 2048 bytes (until address 0x800) is nearly identical. It only is different in the string „hdb1ps1d.q{4,7}1″. That means, that this very first block is not dependent on the different data these games have.
The * 00 00 00 blocks
These are data blocks it seems. The name comes from the fact that they always start with a integer that is small, because it states the number of sub-blocks (at max maybe 18). This * 00 00 00 block’s header is 16 bytes in length. The integers and shorts are little-endian.
| Start | Length (bytes) | Comment |
| 0x00 | 4 | The number of sub-blocks this block has. |
| 0x04 | 4 | The number of 2048 byte sectors the block consists of. |
| 0x08 | 4 | The total data length (raw data without the header information). |
| 0x0c | 4 | Always zero. Maybe the previous is not an integer, its a long value. |
At the beginning of a 2048 byte block this header tells us, how big the block truely is. The total data length is awalys smaller and filled with 00 bytes until a 2048 byte sector is completed. I guess this is because of reading performance. There are 3243 of these blocks when we read through the whole file. But this block consists of sub-blocks.
The * 00 00 00 sub-blocks
Each sub-block is described with a 16 byte header. Thus, we first have to read <number of sub-blocks> times the following header information. The i-th header information (zero-indexed) is at 0x10 + (i * 16 bytes).
| Start | Length (bytes) | Comment |
| 0x00 | 4 | The data length of this sub-block. If the parent block has only one sub-block, this has the same size as the parent block. |
| 0x04 | 4 | If the data is compressed, this is the uncompressed data length. If it is not compressed, than the previous integer is the same. |
| 0x08 | 4 | Unknown |
| 0x0c | 2 | It seems some flags. Most of the time 0, but in 25% of the cases 1280. If it is 1280, then uncompressed data length is always bigger than the data length. Thus, I assume that this indicates if the sub-block’s data is compressed. count | prop. | decimal value 18001 | 75,546% | 0 5821 | 24,429% | 1280 |
| 0x0e | 2 | Also some flags or maybe a type information for the sub-block. It can be of the following values: [1, 6, 7, 8, 9, 10, 11, 12, 13, 14, 15, 17, 18, 19, 20, 21, 22, 23, 24, 25, 26, 31, 32, 34, 35, 36, 37, 38, 39, 40, 41, 42, 43, 44, 45, 46, 47]. E.g.: in 21 we always find qQES data. |
After the main block header (16 bytes) and the sub-block headers (a multiple of 16 bytes) comes the raw data. The sub-block’s data length sum is equal to the main blocks total data length. For each sub-block we can extract its data array.
Writing the blocks with their sub-blocks (using tab) as a tree and also providing an index for each block at the beginning, it looks like the following. I also searched for the „pQES“ substring in the sub-block’s data and marked the sub-block as compressed when 0x0005 value is present at 0x0c. Maybe each block is a scene or level with sub-block data to render it.

Sub-Block Types
| Type | Count [with duplicates](Proportion) / Count Distinct | Compressed | Comment |
| 1 | 6 (0.03%) / 2 | no | Font Images |
| 6 | 1730 (7.26%) / 691 | yes | multi-image, Chipset Images, maybe textures |
| 7 | 1458 (6.12%) / 518 | no | Has some patterns but maybe is not an image, (width=20) |
| 8 | 309 (1.30%) / 272 | yes | Monster sprites and battle effects images, (width=128 or 256), TIM files with header 0x10000000 09000000 or 08000000 |
| 9 | 473 (1.99%) / 444 | yes | Seems to be images (width=512 maybe), looks like gradients |
| 10 | 256 (1.07%) / 221 | yes | Multi-Image data, monster sprites, multi-TIM with header 0x10000000 09000000 |
| 11 | 309 (1.30%) / 201 | yes | Unknown, sometimes contains character sequences at the start (e.g. from a – z), maybe ints that are counted up (hex editor width=8) |
| 12 | 309 (1.30%) / 286 | no | data has these white (0xff) patterns (width=32) |
| 13 | 970 (4.07%) / 375 | yes | character (NPC) sprites images, (width=128), starts with 0x0c000000 |
| 14 | 44 (0.18%) / 35 | yes | character (NPC) sprites images, starts with 0x0c000000 |
| 15 | 2 (0.01%) / 1 | yes | bigger character (NPC) sprites images (width=128) |
| 17 | 5 (0.02%) / 1 | yes | horse sprites images, starts with 0x0c000000 |
| 18 | 5 (0.02%) / 1 | yes | sprites images, starts with 0x0c000000 |
| 19 | 141 (0.59%) / 96 | yes | battle effects (fire, slashes and so on) images |
| 20 | 3 (0.01%) / 1 | no | qQES format |
| 21 | 3317 (13.92%) / 278 | no | qQES format |
| 22 | 72 (0.30%) / 2 | no | qQES format |
| 23 | 44 (0.18%) / 12 | no | maybe image data (has these vertical black lines) |
| 24 | 1062 (4.46%) / 485 | no | qQES format |
| 25 | 27 (0.11%) / 3 | yes | Image, background texture, in tiles, width=256 |
| 26 | 573 (2.40%) / 454 | no | small size, has also a bit these 0xff patterns, maybe level data? (hex width=4), numbers counting down |
| 31 | 1025 (4.30%) / 885 | no | small size, patterns, maybe level data?, some differ only by small changes |
| 32 | 32 (0.13%) / 8 | no | starts sometimes with printline output text and has japanese text, e.g. シナリオ (path=350/6), start with 0x081f0180 |
| 34 | 975 (4.09%) / 957 | no | small size, patterns, maybe level data?, some differ by small changes only |
| 35 | 1576 (6.61%) / 583 | no | small size, patterns (hex editor width=4) |
| 36 | 1506 (6.32%) / 238 | no | small size, patterns (hex editor width=4), rows starts with 0x0*00 |
| 37 | 1033 (4.34%) / 298 | no | small size, patterns (hex editor width=2) |
| 38 | 1377 (5.78%) / 392 | no | small size, nearly same patterns |
| 39 | 976 (4.10%) / 927 | yes (but some are not) | seems to be cut scene script, contains dialog commands, has these CCC (0x00434343) patterns often |
| 40 | 1315 (5.52%) / 893 | no | maybe multi data, has the „text“ header |
| 41 | 1730 (7.26%) / 240 | no | small size, mostly 0x00, small diffs |
| 42 | 213 (0.89%) / 213 | no | has the „text“ header |
| 43 | 24 (0.10%) / 23 | yes | sprite images, starts with 0x0c000000 |
| 44 | 152 (0.64%) / 29 | no (but some are) | has sometimes error messages, maybe scripts? (path=26022/8 -> エンカウントOFF) , (path=637/2 -> job names in japanese), (path=350/11 -> こうげき [attack]), (path=26024/17 -> RIGHT), (path=26027/4 -> メモリーカード), (path=26028/3 -> start menu script?), (path=26022/0 -> battle magic names?) |
| 45 | 140 (0.59%) / 88 | no | some have „{buki,majinyobi} open NG“ ascii header |
| 46 | 612 (2.57%) / 118 | yes (but some not) | contains error messages and japanese text, maybe also messages, start always with 0xe8ffbd27, contains japanese text of inn npc, shop npc etc. some have DQ41章2章 etc. , path=596/8 -> MPが ふえたHP |
| 47 | 27 (0.11%) / 1 | no | contains error messages: c a n ‚ t . g e t . n e w _ f m a p ! ! ( % d ) ( m a x = % d ) |
The 0x60010108 blocks
These blocks make the white spots explained with the gray image above. They are always 2048 bytes in size and start with 0x60010108. In the image they are often „white“, because their data contain trailing 0xFF bytes.
The header seems to be 32 bytes in length.
| Start | Length (bytes) | Comment |
| 0x00 | 4 | Always the 0x60010108 „magic number„ |
| 0x04 | 2 | An index ranging always from 0 to 4, +1 per block. |
| 0x06 | 2 | Seems to be a count number which is always 5. The previous number loops from 0 to 4, thus has five values. |
| 0x08 | 4 | A kind of part number that counts up after the index at 0x04 reaches 0 again. (1-indexed). |
| 0x0c | 4 | An integer |
| 0x10 | 2 | Always 0x8000 which is 128 |
| 0x12 | 2 | Always 0x7800 which is 120 |
| 0x14 | 4 | Unknown number, maybe flags? Forth byte is always 0x38 |
| 0x18 | 2 | Can be 0x0100, 0x0200 or 0x0300 |
| 0x1a | 4 | Always 0x03000000 |
| 0x1e | 2 | Always 0x00 |
There are 26635 of these blocks. When we put the parts (at 0x08) together, for example, from part 1 to 195, we get 40 entries.
I checked: it is not japanese text in some japanese encodings.
Maybe we see here some soundfonts, sound effects or wave files?
Find Japanese Texts
The Japanese Industrial Standards (JIS) tell us, how the japanese text can be encoded in data. It seems to be that the Shift-JIS standard is used in Dragon Quest where every letter has 2 bytes. You can spot Hiragana in the data by looking at two bytes where the first is 0x82. If this happens very often, there is a hiragana sequence.
In the first chapter there is already some dialog. This can help to find the position of the text in the data, if it is not compressed. I just set the hero’s name to „ああああ“.
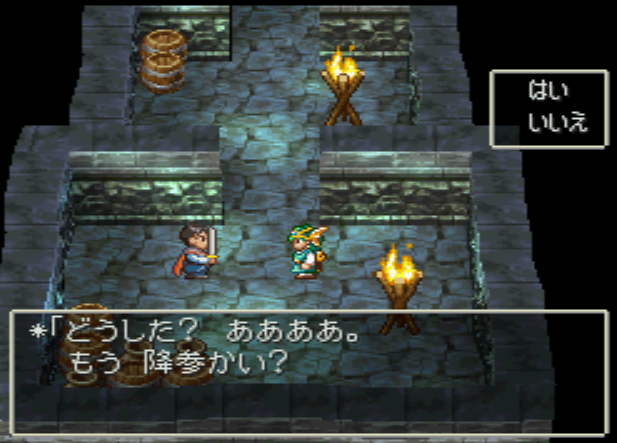
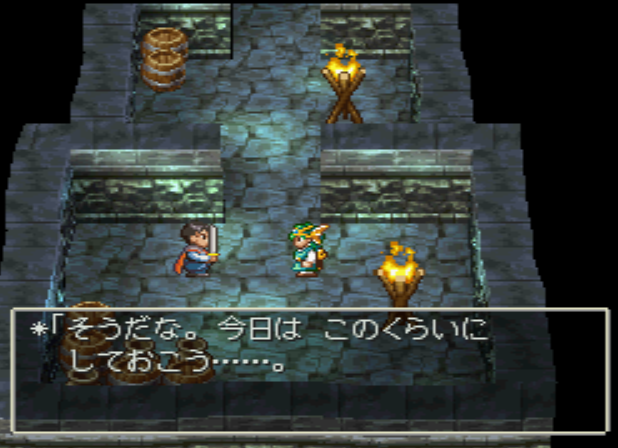
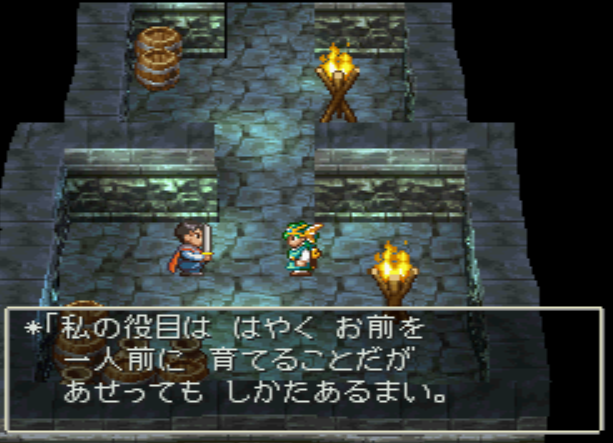
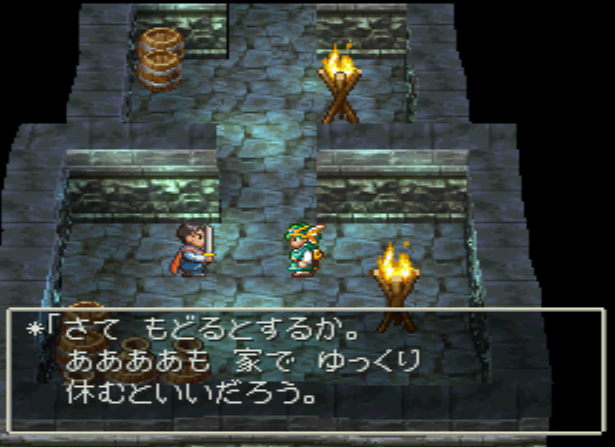
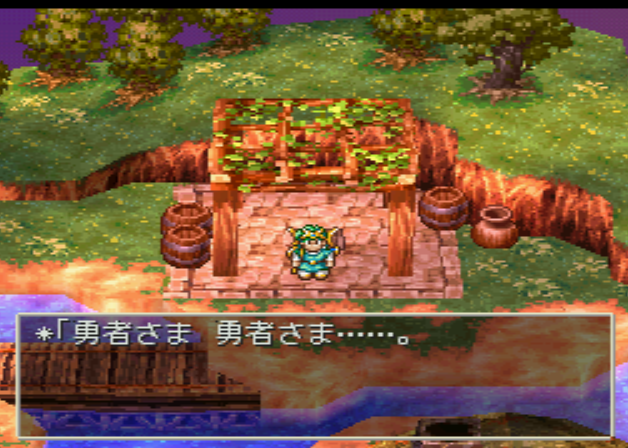
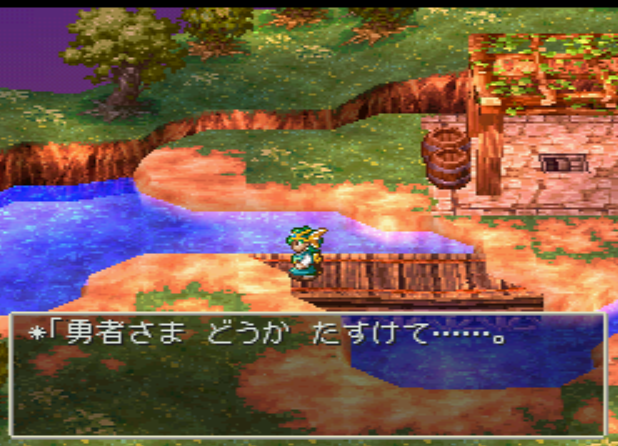
The dialog is:
どうした? <Heroname>。
もう降参かい?
そうだな。今日は このくらいに
しておこう……。
私の役目は はやく お前を
一人前に 育てることだが
あせっても しかたあるまい。
ちて もどるとするか。
<Heroname>も 家で ゆっくり
休むといいだろう。
勇者さま 勇者さま……。
勇者さま どうか たすけて……。
Unfortunately, words of the text above can not be found using typical japanese encodings in the non-image blocks.
Use Dragon Quest VII to find the text
Good news are that Dragon Quest VII is available for both English and Japanese. The English version has the HBD1PS1D.W71 file, while the Japanese version has the HBD1PS1D.Q71. We search for the data blocks that differ the most, because they had to change the dialog texts completely. Based on the sub-blocks type information I compared them all using hashes on the binary data. In cases where the hashes do not match, I assume that they changed a lot. The most suspicious are listed in the table:
| (has some header data, than there comes the bytes, jp is always larger in size) type 23: 1911 sub-blocks vs 1911 sub-blocks 877 distinct hashes vs 877 distinct hashes 877 en no match vs 877 jp no match |
| (same header like 23) type 24: 167 sub-blocks vs 167 sub-blocks 167 distinct hashes vs 167 distinct hashes 167 en no match vs 167 jp no match |
| (same header like 23) type 25: 37 sub-blocks vs 37 sub-blocks 37 distinct hashes vs 37 distinct hashes 37 en no match vs 37 jp no match |
| (same header like 23) type 27: 7 sub-blocks vs 7 sub-blocks 6 distinct hashes vs 6 distinct hashes 6 en no match vs 6 jp no match |
| (beginning is same but then it changes in some byte, need to look deeper, En size smaller than Jp size, seems like scipts, some output text is translated, looks like multi-data [image-data]) type 31: 2597 sub-blocks vs 2596 sub-blocks, DIFF Unknown 1772 distinct hashes vs 1771 distinct hashes 1769 en no match vs 1768 jp no match |
Interestingly, type 23, 24, 25 and 27 share the same header. A closer look reveals that in fact the binary data changes a lot. What we can learn from that is how the sub-blocks looks that contain very probably text. We can use this knowledge to search through the types of DQ IV again. It turns out that type 40 and 42 has the same header information. We will call them text-blocks.
Text-Blocks and their huffman coding
| Start | Length (bytes) | Comment |
| 0x00 | 4 | An offset that points to the near end of this block. We call it „a“. If we read there a 4-byte int, it has the same value. |
| 0x04 | 4 | Unique ID. If ID is same, code is also the same. The first scene in the game has ID 0x0000006C. IDs are never longer than 2 bytes. |
| 0x08 | 4 | An offset. We call it „c“ for now. It will tell us where to read the „huffman code“ (begin index). |
| 0x0c | 4 | An offset. We call it „d“. Sometimes 0. Tells us where to read the „huffman tree“ (end index). |
| 0x10 | 4 | An offset. We call it „e“ for now. It will tell us where to read the „huffman code“ (end index). |
| 0x14 | 4 | Seems to be often zero. |
The text-block header has six 4-byte integers. The offset „c“ is very often 24, so I assumed that is a start point of a byte array after the header information in the block. „c“ < „e“ < „d“ (if d is not zero) is always true.
The „c-e range“ covers the huffman code (the bit information) that has a length which is always a multiple of 4 (it has trailing zeros). After „e“ comes a 4-byte int, antoher 4-byte int and a 2-byte short. The next „e-d range“ contains the huffman tree: the actual japanese letters and some node information. There is also the „d-a range“. If d is zero then this range does not exist and we set d to a (which means the „e-d range“ becomes „e-a range“). At „a“, after the same 4-byte int value, there is a 4-byte int counter (but often zero). If not zero we can read counter * 8 bytes and reach the end of the block.

Two ranges seem to be most relevant: the huffman code and the huffman tree. In the huffman tree range are byte-pairs with the actual japanese shift-JIS letters. If the first byte is not 0x80 (indicates a node) or 0x7f (indicates a control character), we have to swap the bytes and add 0x80 to get the actual letter, for example, 0x835f which is ダ. In case of 0x80, it is a node with a number. The 0x7f** are special control characters such as new line, end of text or <Heroname>. Each letter always occurs only one time. In order to uncompress the huffman coding, we have to understand the trees first.

The text decoding routine
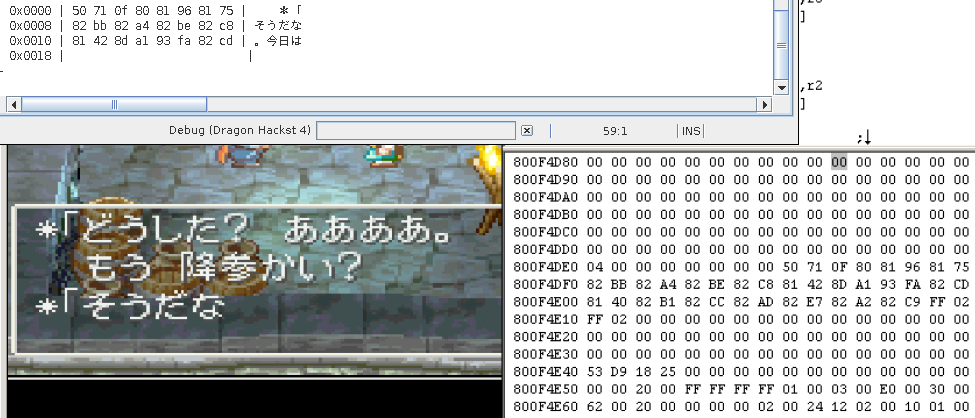
In order to draw the text to screen, the dialog has to be decoded resp. decompressed first. Dialog text is decoded line-by-line and written to RAM at 0x800F4DEB (every time it is overwritten). You can define a memory breakpoint using PCSX 1.5 with Debugger to see it. The preceding 0x50710F80 value is only in RAM when the textbox is shown, otherwise 0x00000000.
In the PSX-EXE the decoding routine seems to start at 0x8008F3BC. It is called at 0x8002D084. When the routine returns, one decoded 2-byte Shift-JIS letter is in r2 (register 2). r3 and r6 are pointers to the huffman tree. r6 points to the start and r3 points to the middle of the tree. These two different offsets are used for the left and right side of a branch. The routine uses the offsets to decide where to jump next. The node number (e.g. 0x8149 minus 0x8000 = 0x0149 = 329) tells us how far we have to jump to reach the next node or leaf. With this information we can construct the trees.
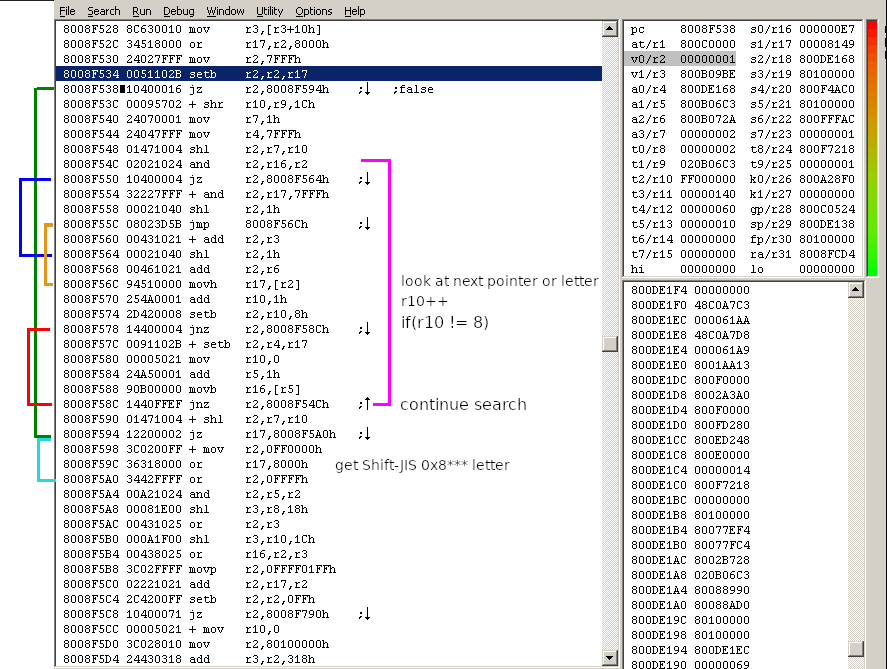
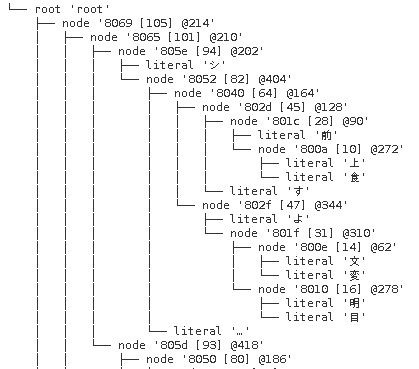
The huffman code is the actual text but encoded in bits. By decoding the bits and traversing along the tree (0 = left, 1 = right), we get the japanese text. For each byte we read from right bit to left bit.

| Control Character (0x7f**) | Meaning |
| 0x7f1f | Heroname |
| 0x7f02 | New Line + Tab |
| 0x7f0b | |
| 0x7f04 | |
| 0x7f0a | Blinking Cursor, Wait for User Input |
| 0x0000 | End of Text |
Translation Preparation
In order to translate the dialog texts, we have to extract them. This is done by the translationPreparation method in the HBD1PS1D class. For each distinct textblock (using the unique IDs) we create a csv file with the name of the ID in hex (e.g. 006C.csv). Each row of the CSV file is a dialog segment, usually ending with the {0000} control character. The CSV is used to enter the translated text per dialog segment.

An additional offset information in the third column of the CSV tells us the byte offset from begin of the text textblock to the byte where the huffman coding starts. This way we can tell by the byte-distance what segment will be loaded in the game. Once we replace all the huffman code with translated texts, the start offsets of the segments are also changed (because the translated text is in bits not exactly as long as the original text). When the game wants to load a certain dialog (e.g. on offset position 0x01F2) we have to correct this offset to the actual start of the translated text. That is why we keep the original offset in order to map it to the new one later.
The extraction creates 925 files (2.8 MB). They can be downloaded in a ZIP file with the following link.
Where does the dialog pointers come from? Finally, the cut scene script!
We can check what data is loaded into RAM for the first scene:
(type 44) "town of hoffman" assembler code
26022/1 from 0x00102448 to 0x0013b890 | length: 234568
(type 46, lz) "can't get new_total_seq" assembler code
26046/14 from 0x0013bf04 to 0x0013e3bc | length: 9400
(type 37, pattern)
1071/14 from 0x0018bfc8 to 0x0018c028 | length: 96
26051/13 from 0x0018bfc8 to 0x0018c028 | length: 96
26117/7 from 0x0018bfc8 to 0x0018c028 | length: 96
(type 36, pattern)
1071/11 from 0x0018c7a8 to 0x0018c91c | length: 372
26051/11 from 0x0018c7a8 to 0x0018c91c | length: 372
26117/6 from 0x0018c7a8 to 0x0018c91c | length: 372
26607/5 from 0x0018c7a8 to 0x0018c91c | length: 372
(type 35, pattern)
1071/10 from 0x0018c91c to 0x0018c9d0 | length: 180
26051/10 from 0x0018c91c to 0x0018c9d0 | length: 180
26117/5 from 0x0018c91c to 0x0018c9d0 | length: 180
26607/4 from 0x0018c91c to 0x0018c9d0 | length: 180
(type 34, pattern)
26051/6 from 0x0018f188 to 0x0018f284 | length: 252
(type 31, pattern)
26051/0 from 0x001c8c74 to 0x001c8d94 | length: 288I found out that there is compressed assembly code which comes after the textblock and it is also written to RAM @0x8013BF04 in decompressed form (26046/14). I named it „can’t get new_total_seq“-script, because it has this debug message at the beginning. I checked if any code is executed in the first scene, but this is not the case.
I used another debugger to set a breakpoint when someone writes to 0x800F4E40, the place where the dialog pointer is stored. This revealed that it happens in code 0x80086A98: it writes r2, which has the calculated dialog pointer 0x5AD91815 to RAM. When we trace back the call stack (see attachment), we come to an address that is 0x80128B6C, so it is maybe assembly code loaded from HBD1PS1D.Q41. In fact, I checked all script data in HBD1PS1D.Q41 and found that one script is also loaded in RAM @0x80102448 for the first scene: it is the 26022/1 block and it contains at the beginning the name ホフマンの町 (engl. Town of Hoffman). Thus, the Town of Hoffman script is the caller to a lower level function to present the very first dialog. When you set a breakpoint to 0x80128B6C, you stop there as soon as you press a key when the hero the first time stands up. So this part seems to decide what happens next, which is showing dialog by looking at 0x5AD91815 (the huffman code location).
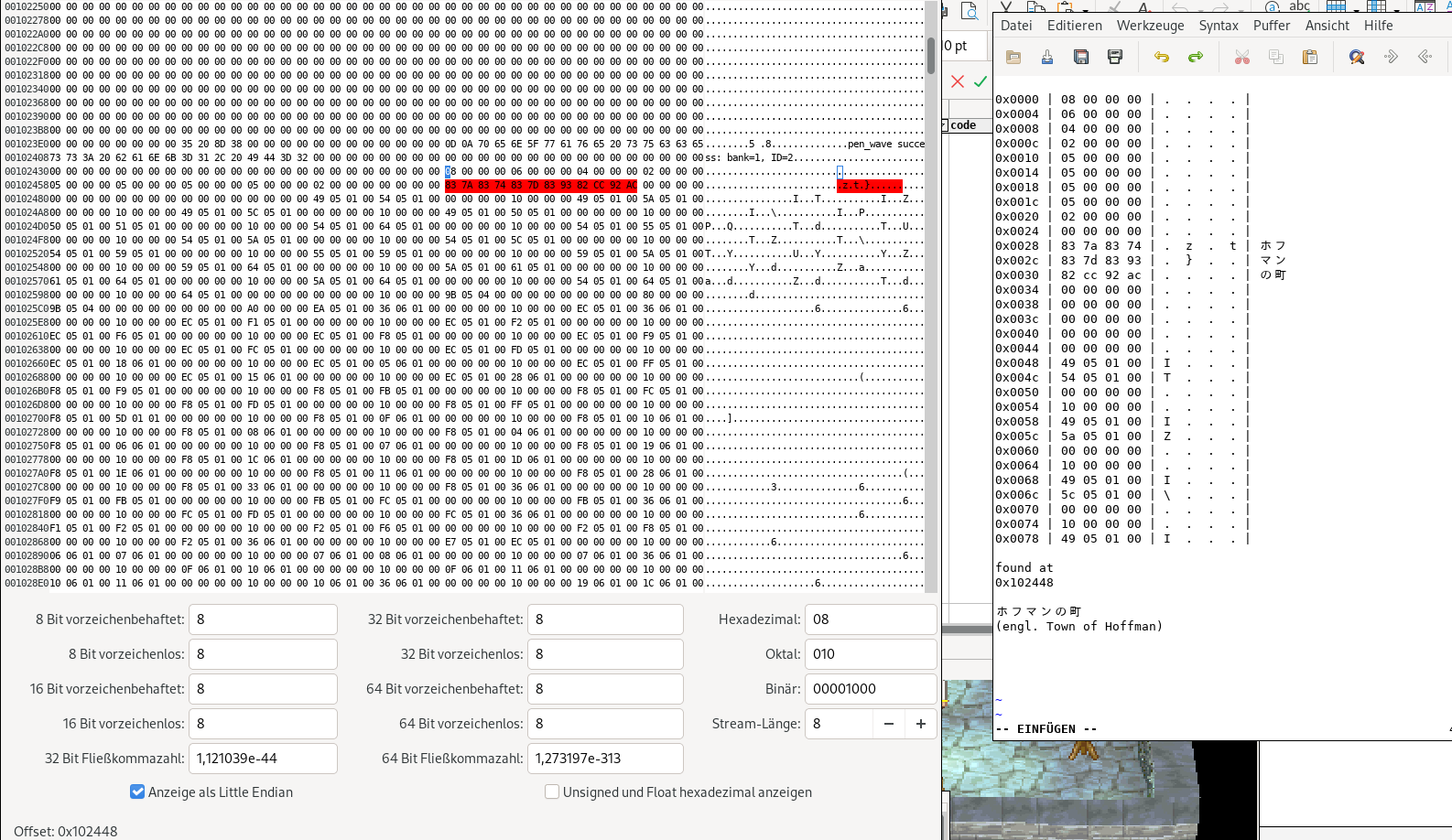
I checked the origin of the dialog pointer by debugging the assembler code in detail and finally found out that it is loaded from a file that describes the cut scene. The 06C00F91 value means that it will jump 0xF91 bits in the huffman code to get the right starting point. The 0x06C is the text id 006C (first scene). In the 26046/6 block (type=39) is the compressed cut scene script.
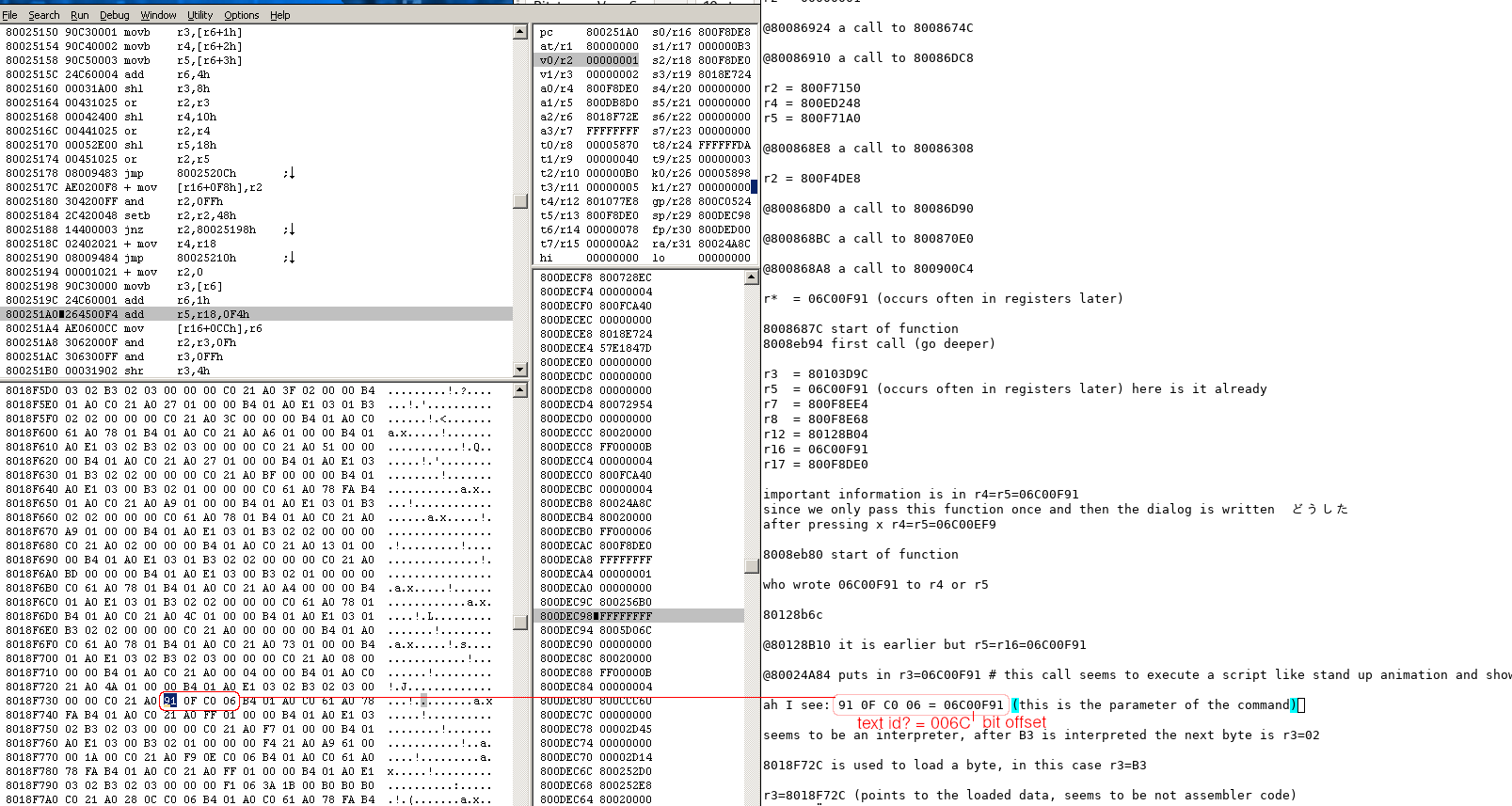
I picked another textblock and checked the corresponding cutscene code. It seems that ‚C0 21 A0‘ is the dialog command. The parameters are: ‚C0 21 A0 <2 Byte for Bit Offset> <2 Byte for Text ID>‘ (see the examples in the screenshots). I created a second version of the translation files, this time with the bit offsets and the predicted dialog command. Seems to be correct. Thus, we maybe just have to replace at these places the bit offset.
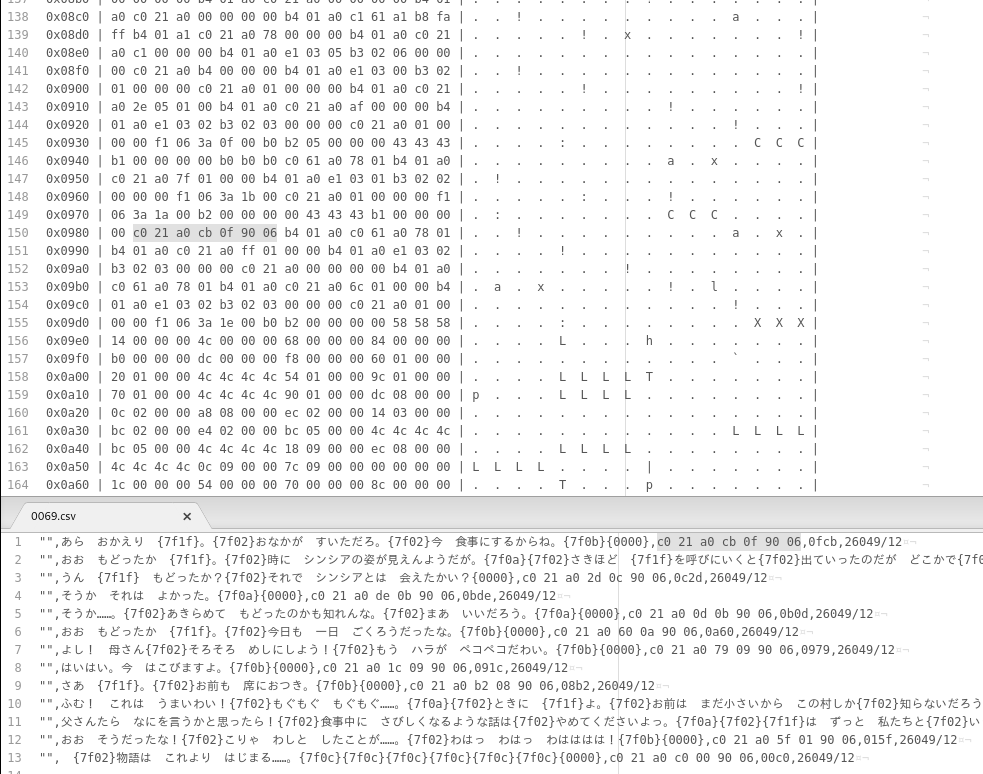
Below are the texts, but this time with the predicted dialog commands.
Translation Embedding (Second Attempt)
Unfortunately, many cut scene blocks are compressed. So we have do decompress them, replace the bit offsets and compress it again. Mandy found out that Heartbeat used the LZSS0 algorithm by using a tool called QuickBMS (comtype_scan2 script). The LZSS implementation by crosswire with a 0-filled buffer correctly compresses all cut scene blocks.
As a proof of concept I swapped some dialog pointers in the first cut scene. Now our solider has the japanese dialog of Cynthia (シンシア).

Understanding the cut scene script
Mandy Wilkens investigated the commands in the cut scene script and came to the following findings: https://github.com/mwilkens/dq4psxtrans#dq-scripting-language
CD-ROM Pointers
As Chicken Knife points out correctly:
the translation can’t be done justice by compressing an English script into the original space for the Japanese text. English text takes up appx 2.5 times the space that Japanese text with kanji takes.
romhacking forum
When we later expand the text in a level, it will need more sectors on CD-ROM which causes the shift of all levels after that. Therefore, we have to find the place where the game loads a level to adjust these sector addresses.
By using the no$psx emulator, we can open Window > TTY Debug Message and Enable > Log CDROM commands. Once the game loads a certain sector range from disk, we can see the commands.
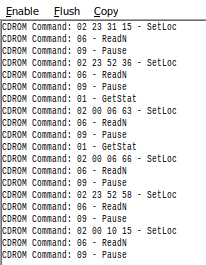
When we go in the game into the levels the CDROM has a SetLoc command to these sectors.
| mm | ss | cc | Level | Text ID |
| 23 | 46 | 64 | Cellar | 0x006c |
| 23 | 49 | 41 | Town | 0x0067 |
| 23 | 48 | 30 | House Top Left | 0x0069 |
| 23 | 49 | 01 | House Top Right | 0x0068 |
| 23 | 51 | 72 | House Bottom Right | 0x0065 |
There are CDROM registers in the playstation where the location is written. While the command is written to 0x1F801801 (SetLoc = 0x02), the parameters are written to 0x1F801802. The parameters express in hex representation the minute (0x00 to 0x73), second (0x00 to 0x59) and 1/75 second (0x00 to 0x74, because a second has 75 sectors) to jump to a certain 2048 byte sector on disk. In assembler code of the game the writing to the CD Parameter Fifo happens at 0x8009BDF4. It turns out that the parameters are read from 0x800DEAD0. The call 0x8009D950 located at 0x80059078 writes them to 0x800DEAD0. This function calculates from a sector address (in r4) to the minute, second and 1/75 second representation. In r9 and r10 we find the begin and end sector address.
From cellar to town: r9=0001A23A r10=0001A287
From town to cellar: r9=0001A170 r10=0001A19C
When we iterate over the folders (or levels) in the HBD1PS1D.Q41 file, we can calculate the expected sector address:
sec=106864 secHex=0001A170 lastSecHex=0001A19C text id 006c = cellar
sec=106908 secHex=0001A19C lastSecHex=0001A1BF text id 006b
sec=106943 secHex=0001A1BF lastSecHex=0001A1E4 text id 006a
sec=106980 secHex=0001A1E4 lastSecHex=0001A212 text id 0069
sec=107026 secHex=0001A212 lastSecHex=0001A23A text id 0068
sec=107066 secHex=0001A23A lastSecHex=0001A287 text id 0067 = town
sec=107143 secHex=0001A287 lastSecHex=0001A2EF text id 0066
sec=107247 secHex=0001A2EF lastSecHex=0001A316 text id 0065
After backtracking a lot of code, it turns out that the sector address and length (number of sectors) is stored in the PSX EXE. Using a 32 bit address, they use a 12 bit length and 20 bit offset encoding: length | offset. For instance, the town level has 04D | 1A23A, because 0x0001A23A is the start sector and 0x4D (decimal 77) are the number of sectors the level has on disk.
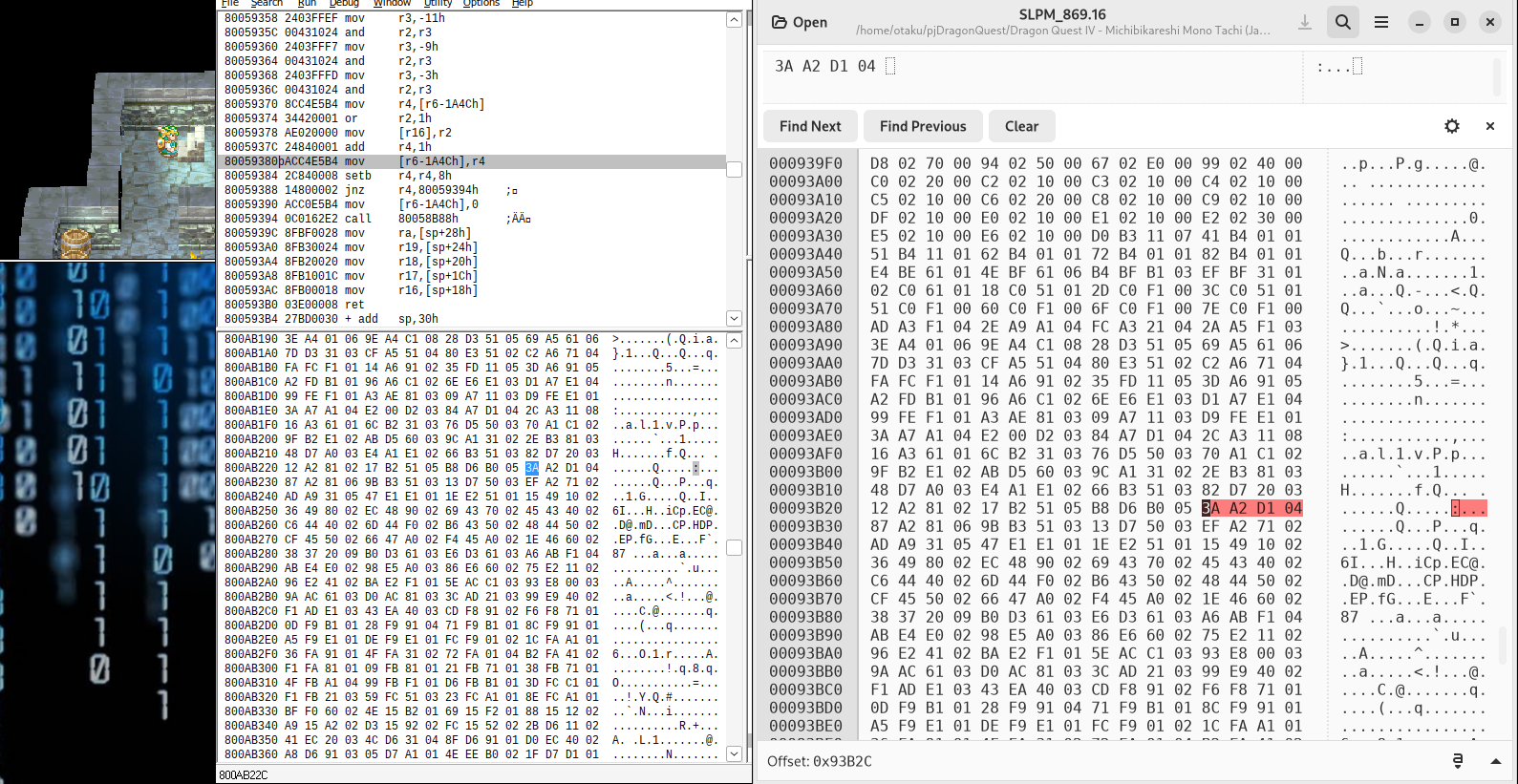
With this information, we can calculate these addresses for each level:
from:0001A170 to:0001A19C size:0000002C addr:02C1A170 storeAddr:70A1C102 text id 006c cellar
from:0001A19C to:0001A1BF size:00000023 addr:0231A19C storeAddr:9CA13102 text id 006b
from:0001A1BF to:0001A1E4 size:00000025 addr:0251A1BF storeAddr:BFA15102 text id 006a
from:0001A1E4 to:0001A212 size:0000002E addr:02E1A1E4 storeAddr:E4A1E102 text id 0069
from:0001A212 to:0001A23A size:00000028 addr:0281A212 storeAddr:12A28102 text id 0068
from:0001A23A to:0001A287 size:0000004D addr:04D1A23A storeAddr:3AA2D104 text id 0067 town
from:0001A287 to:0001A2EF size:00000068 addr:0681A287 storeAddr:87A28106 text id 0066
from:0001A2EF to:0001A316 size:00000027 addr:0271A2EF storeAddr:EFA27102 text id 0065
For each folder the stored address (inverted byte order) can unambiguously be found in the PSX EXE (see findPointerToFolders method, except two folders with index 26401 and 26402). When we change in RAM at 0x800AB22C the town address 0x3AA2D104 to another level address, the game loads this level instead. Thus, we can manipulate where the level should be loaded, especially when it has another sector and length because we expanded the text.
New Codebase
After learning from the insights above I started a new codebase in the github repository in august 2022. This allowed to rename and refactor some parts of the code.
Since this code should be able to patch the Dragon Quest 4 CD, the project focuses on reading and writing data in the IO package. There are some helper classes for that:
- DragonQuestReader.java – abstract class for reading tasks
- DragonQuestWriter.java – abstract class for writing tasks
- DragonQuestInputStream.java – helps in reading data from input stream
- DragonQuestOutputStream.java – helps in writing data to output stream
- Converter.java – converts binary data in various formats
Reading (and writing) happens hierarchically according to the hierarchy of the data:
- DragonQuestBinaryFileReader.java – reads the whole disk image file (*.bin file). In this image it recognizes three files: HBD1PS1D.Q41, SLPM_869.16 and SYSTEM.CNF. The HBD1PS1D.Q41 file is further processed by:
- HeartBeatDataReader.java – it recognizes the HBD1PS1D.Q41 data as a list of entries. The most interesting ones are the folder entries (* 00 00 00 blocks). Thus, they are read with:
- HeartBeatDataFolderEntryReader.java – a folder has different file types as already mentioned (the * 00 00 00 sub-blocks). We are interested in two types: files with text content and files with script content. Therefore, two readers are used:
- HeartBeatDataTextContentReader.java – here, the huffman trees and huffman bits parsing happens.
- HeartBeatDataScriptContentReader.java – script commands are read for later dialog pointer changes.
- HeartBeatDataFolderEntryReader.java – a folder has different file types as already mentioned (the * 00 00 00 sub-blocks). We are interested in two types: files with text content and files with script content. Therefore, two readers are used:
- HeartBeatDataReader.java – it recognizes the HBD1PS1D.Q41 data as a list of entries. The most interesting ones are the folder entries (* 00 00 00 blocks). Thus, they are read with:
With this we can read the data into Java RAM:
IOConfig config = new IOConfig();
DragonQuestBinaryFileReader binReader = new DragonQuestBinaryFileReader(config);
File inputFile = new File(folder, "dq4.bin");
DragonQuestBinary binary = binReader.read(inputFile);This yields to the following data hierarchy:
DragonQuestBinary
HeartBeatData
HeartBeatDataEntry (in case of HeartBeatDataFolderEntry)
HeartBeatDataFile
HeartBeatDataFileContent
(can be *TextContent or *ScriptContent)
HeartBeatDataFile
HeartBeatDataFile
...
HeartBeatDataEntry
HeartBeatDataEntry
...
PsxExe
SystemConfigWith this, we are able to manipulate the data and write it. Translation attemps are implemented in the Translator. The challenge is to change the HeartBeatDataTextContent in such a way that the game loads the translated text. In a text content a (huffman) bit string encodes several dialog lines in one sequence. They are just concatenated and separated and null terminated (indicated with {0000}). To give an example, here is a sequence of dialog using the alphabet:
abcdef{0000}ghijk{0000}lmopq{0000}rst{0000}In the script content commands point to these sequences. In the example, there would be commands which point to a, g, l and r with an offset relative to the beginning of the sequence.
abcdef{0000}ghijk{0000}lmopq{0000}rst{0000}If the dialog lines are now translated and changed, for example to …
uv{0000}wx{0000}yz123{0000}456789{0000}… then the pointes would not point anymore to the beginning of the dialog lines. Therefore, we have to make sure that the following pointers are changed in the example:
- a -> u
- g -> w
- l -> y
- r -> 4
To do that, we have to know which commands in the script content point to a, g, l and r so that we change them to the new offsets for u, w, y and 4. There are two places where these pointer are stored. One is actually the text content itself (HeartBeatDataTextContent). It can contain a list of entries which point to the dialog lines. These entries are key-value pairs. I assume the key is a variable which is used in the script to show dialog depending on some conditions. Another place is for dialog pointers is the script content (HeartBeatDataScriptContent). A script is a sequence of commands (like assembler). There are two commands which are used to store dialog pointers in CPU register: ScriptStoreEntry and ScriptSpecialStoreEntry. In their parameters they mention the text ids and bitoffsets. To know which command points to which text we make a search effort in HeartBeatDataFolderEntryReader. After the folder is read, we look for pointer associations between text contents and dialog pointers. When we found them, we store the association using the HuffmanCharacterReferrer interface. It refers to the exact huffman character in the sequence of characters (in our example a, g, l and r).
The big question is now, if we found all pointers to all dialog lines in order to safely translate them and change their referrers. From 12870 dialog pointers found in text contents (the key-value pairs), 12868 have a correct reference to a dialog start which is a 99,98% coverage. The remaining 2 which where not found seems to occure in a text content which does not look like it is used in the game (textId=043f). All of the 3658 found store commands correctly point to the dialog lines. However, more importantly we have to ask the other way around: How many dialog lines are covered? When we take every dialog line in every text content and check if the dialog line has a referrer (see InspectImportedData), we get 915 text contents which are completely covered and 10 which have missing references. Thus, 98,91% of the text contents can be translated. In terms of dialog lines (the abcdef{0000} sequences) we have 16695 dialog lines (excluding ダミー ‚dummy‘ lines) where 16312 of them have a referrer.
When text is replaced in the patching process, I try to change as little as possible to not break the game. In HeartBeatDataTextContentWriter the text content is written. The trick is to use the huffman bits space and fill it with zeros to maintain the file structure. Offsets are updated accordingly.
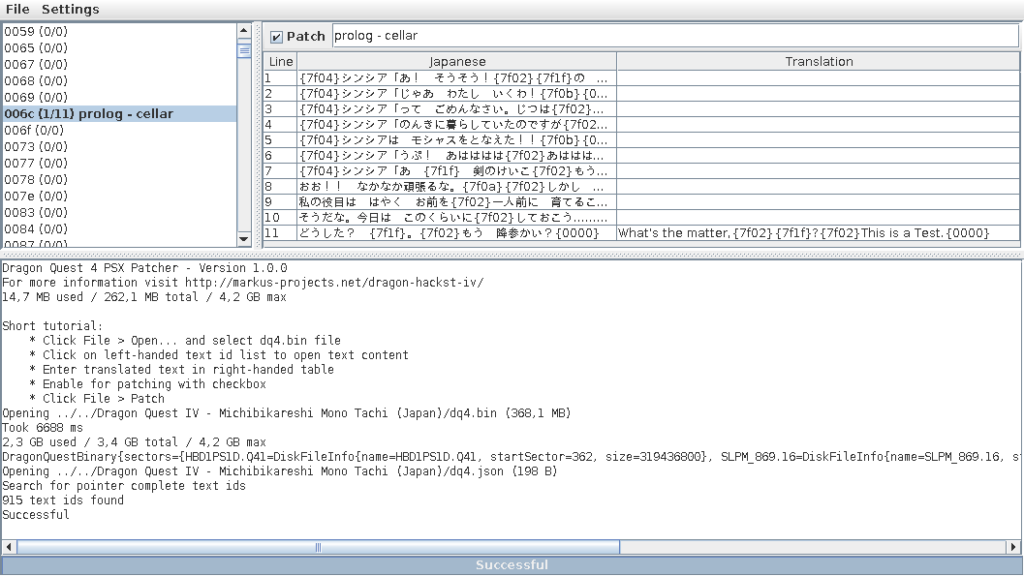
Dragon Quest 4 PSX Patcher — Graphical User Interface
I implemented a small Graphical User Interface (GUI) with Java 8 Swing called dq4psx-patcher. It allows you to open the dragon quest 4 image disc (*.bin file) and list all text contents (text IDs) in the left-handed list. You can open a text content and see all its dialog lines which can be translated and saved. Text contents can be named to identify them. It is recommended to have around 4GB RAM for this application, since the whole game data is parsed. Text has to end with control character {0000} so that the game knows the end of a dialog line.
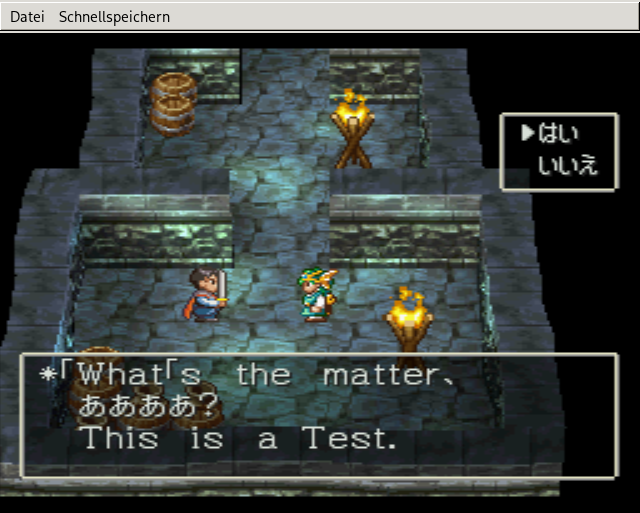
After patching the game shows the translated text. For not translated dialog lines the text ID and line number is written (e.g. „006c 10. Line“). This is helpful to locate in the game which dialog is loaded.
Download the latest version here: dq4psx-patcher.jar. Needs Java 8 or above. Make sure to allocate enough RAM. You can create a *.bat file on Windows and add the following:
java -Xms3500m -jar dq4psx-patcher.jarIssues, suggestions for improvements, questions can be sent to me via mail to dq4psx-patcher@markus-projects.net.
To make it clear: the software is provided „as is“, without warranty of any kind, express or implied, including but not limited to the warranties of merchantability, fitness for a particular purpose and noninfringement. In no event shall the authors or copyright holders be liable for any claim, damages or other liability, whether in an action of contract, tort or otherwise, arising from, out of or in connection with the software or the use or other dealings in the software.
Hello, I think to have dragon quest 4 for ps1 would be the best way to play dragon quest 4 because the only way to play it is on ds and its s tiny and the nes version its so old, my dream is to play it on my ps1 on my crt that would be espectacular, I hope you finish the job one day it would be EPIC
Don’t give up! I’m currently playing through Dragon Quest 1 and 2 on the SNES and hopefully the Dragon Quest 3’s HD-2D Remake will be out soon, and after that i really hope your translation on part 4 for the PSX is done!! 🙂
Amazing work so far! It seems you sir are a genius, the way you are finding possibilities to translate it. Can’t wait to play the finished translation, hopefully it will also encourage more people to play this gem!
Is there any way i can support the translation?
Haven’t seen any update in a while. You still chugging away or has this project been canned?
I’m eagerly awating the day that a fan translation of DQ4 is released. The official translation of the DS version is simply awful, and the NES version’s graphics genuinely hurt my eyes to look at. I pray that, someday, I can play a version of Dragon Quest IV that is both pleasant to look at, and has a translation that is accurate and faithful to the original Japanese script and fully in English. No goofy accents, no non-English words peppered throughout the script, no puns. A true translation of DQ4! Take your time with this project, and make it the best it can be!
Hi, I understand that people looking forward to a translation. However, the patching of the game is still in an early state. I hoped that there could be other technicians (like computer scientist students) who help with the technical issues. Since the sprint in March 2023 I did not work on the project (busy job and life). One has to debug the actual game’s assembler code to check if the patching does the correct thing. Any technical help from interested people is very much appreciated.
Don’t give up mate, you are doing God’s work. I’d love to assist anyone way I can donate some money to assist?
I aplaud your efforts Markus. Hopefully someone with the right skill set will tag along and help you with the project. It would be great to play a fan translation of this beautiful game one day. Godspeed!
In case this is useful, the large font is actually stored in the PSX-EXE at the near end of the file, judging the look and my guess was right. Looks like the small font one if seen using 16bpp but using the font CLUTs from the VRAM doesn’t work. This is in an atlas format and uses a strange compression method, and I guess, it’s in 2bpp (not sure which 2bpp) in 2D format and stacked in 2 or 3 images in stripes, one is unaltered, one is slanted, and one uses an unknown method
Swapping the DW7 font atlas sheet for the DQ7 and DQ4, and DQ7 with DQ4, some of the letters looks distorted in a sliding window manner, some looks normal, and some looks completely destroyed. The header stores how the letters in the atlas picked by the system. The part before the font is uncertain, but DQ7 and DQ4 are larger than DW7 and corrupting/swapping this causes the menu texts to disappear and freezes the game when selecting the options and when interacting with NPCs or objects with messages (small font configuration, text-box-related code, and compressed texts?). Btw, what does the DQ/DW7 discs hide? Accessing the debug menu from both discs proved no differences and no crashes, disc change is only to disc 2 and no reverse via DISCCHG map, even the ending movie, maps for prerendering the ending movie, and the after ending movie maps are also available in the disc 1. The only visible difference is the HBD1PS1D file size
DQ4 can handle more than 4 letters in character names but freezes the menu if there’s a character with more than 4 letters, 5 is okay for some or a few parts of the menu + battle screen. We can pick from DW7 for handling long and short names
At least, I want to see the DW7 large font to be swapped with DQ7 and DQ4 as these looks interesting. DQ7 font is the same as DW7 but serif + different “a” “b” “d” “g” “p” “q” “y” (feels like Comic Sans but serif lol), DQ4 font is totally different from DW7 and DQ4 (except for numbers and punctuations) and this looks like an effort for the official English translation and you can see it used in the DW7 opening texts with little differences. The Japanese fonts are always larger than the English one + some kanjis replaced with item symbols (not sure if the replaced kanjis means the same, you can compare it on the DQ7/DQ4 and DW7 small fonts) and DQ4 has a few additional symbols but no “&” as in DW7 (only appears one time in the present time tula player tower somewhere in the series of plot Slachi events, something like “Do you want to x & x [and so on]?” and a yes-or-no window appears)
(I don’t have knowledge in computer science and coding, just curious about these games hidden facts)
Any way I can assist with the tl side of things?
Sorry, first the technical issues have to be solved.
Hey, I am just glad to see that this project is still being worked on. I just wanted to add my voice to the crowd to show how much interest there is in a translated version. Please, don’t give up!
I don’t know how to any of this. I wish I could help in some way
This is an amazing project and clearly intensely difficult. I hope you know that people are still cheering you on! I have no idea if you’re working on it but if so, we eagerly await the day this is complete!